2026.03.04 Gemini 3.1 Flash-Lite 预览版深度解读:低成本高吞吐模型该怎么用
发布日期: 2026-03-04Gemini 3.1 Flash-Lite 预览版的核心定位不是“追求最强智能”,而是“在足够好质量下,把延迟和单位成本压到更低”,适合高并发、任务标准化、可路由分层的生产场景。对企业来说,这个模型最有价值的地方是:它能把大量本来不需要重型模型的请求,从昂贵模型池里分流出去,从而显著优化整体 AI 成本结构。
信息图总览
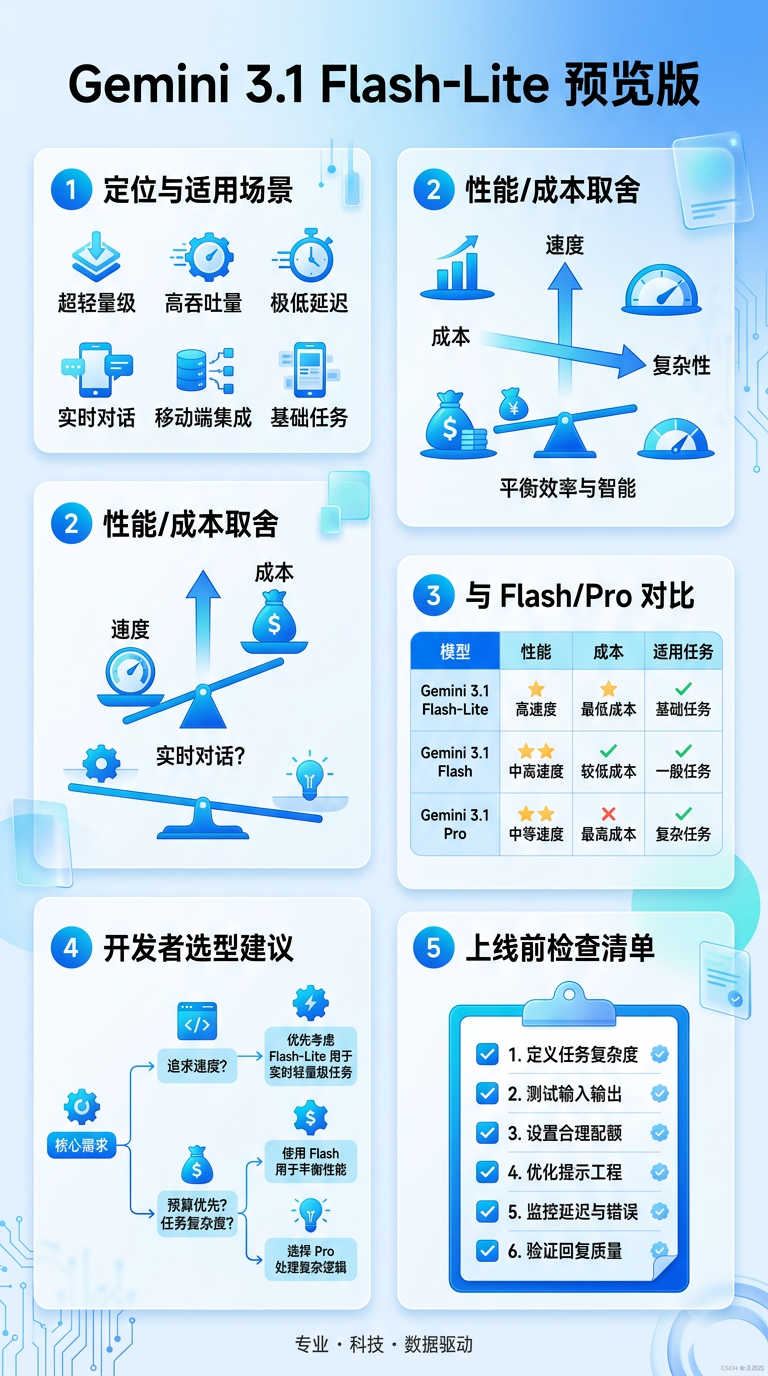
一、这款模型到底是干什么的?
从官方页面和公开技术信号来看,Gemini 3.1 Flash-Lite 预览版是 Gemini 3.1 系列里的轻量高吞吐成员。它并不强调“每道题都深度推理到底”,而是强调“在真实业务里更快地完成大量日常请求”。这意味着它特别适合如下任务:规则清晰的文本处理、批量摘要、分类路由、内容审核、结构化抽取、基础客服自动化、多语言轻翻译等。你可以把它理解为 AI 系统里的“主力工兵模型”:单次不一定最华丽,但在规模化生产里性价比非常高。
二、为什么它值得关注:不是便宜,而是“可规模化便宜”
很多团队会把“模型便宜”简单理解为每次调用单价低,但实际部署里更重要的是总吞吐成本和峰值稳定性。Flash-Lite 的意义在于:它通常能在更低单价下承接大量中低复杂度请求,使你可以把资源预算集中给真正需要更强推理的请求。这个架构收益是乘法级的——不是省 5%、10%,而是当请求量上来后,整体成本曲线明显变平,同时响应速度更可控。对于要做线上产品(尤其是有免费层、试用层、或海量自动化任务)的团队,这个差异非常实际。
三、和 Flash / Pro 怎么分工最合理?
| 模型层级 | 适合任务 | 优势 | 注意点 |
|---|---|---|---|
| Flash-Lite | 高频标准任务、批处理、基础对话 | 低延迟、低成本、高吞吐 | 复杂推理上限有限 |
| Flash | 中等复杂任务、实时交互 | 速度与能力平衡 | 成本高于 Lite |
| Pro | 复杂推理、关键决策、严谨生成 | 能力最强、鲁棒性高 | 成本和时延最高 |
真正成熟的系统不会只选一个模型,而是做“模型路由”:先让轻量模型处理大多数请求,再把小部分高复杂度请求升级到更强模型。这种分层策略是 2026 年主流 AI 工程团队的共识。
四、预览版怎么用才稳?
“Preview” 不代表不能上生产,但意味着你必须加工程护栏。第一,给模型版本做明确 pin(不要盲目跟随默认版本);第二,关键业务路径保留降级与回滚开关;第三,输出质量要有抽样评估与自动监控;第四,提示词和结构化输出协议必须收敛,避免调用行为漂移;第五,预算侧要设置 token 和 QPS 限额,防止意外流量击穿。很多团队上线失败不是因为模型能力不够,而是把预览模型当稳定协议来用,忽略了版本变化和行为漂移管理。
五、给开发者的落地建议(直接可执行)
如果你准备接入 Gemini 3.1 Flash-Lite,建议按这个顺序落地:先挑一个高频、标准化、可量化的任务做试点(例如评论分类或客服首轮分流);然后建立 Lite/Flash/Pro 三层路由规则(按复杂度、风险等级和SLA做分流);接着定义统一输出 schema 并做解析兜底;最后再做成本与质量双指标观测(例如每万请求成本、平均延迟、人工复核通过率)。这样你拿到的不只是“能跑起来”,而是“可控可迭代可扩展”的生产能力。
六、结论:它不是替代一切的大脑,而是最关键的成本杠杆
Gemini 3.1 Flash-Lite 预览版最适合作为你的“流量承接层”。它让 AI 系统从“每次都用大模型硬打”升级为“按任务分层调度”,这才是企业级 AI 从 Demo 走向规模化运营的关键一步。如果你问一句最实在的话:该不该上?答案是该上,但别裸上——配好路由、监控、回滚和预算护栏,再上,这样你会又快又省,还不容易翻车。