2026.03.04 OpenClaw 安全实践指南深度复盘:该学什么,先补什么
发布日期: 2026-03-04这份《OpenClaw Security Practice Guide》是目前少见的、明确面向“高权限 AI Agent 实战场景”的安全指南,结构完整、可执行性强、覆盖了从事前规则到事后巡检的闭环。但它并不等于“上了就安全”,真正的短板在于:大量防线仍依赖 Agent 行为自律,而非系统层硬约束。本文给出可落地的升级路线,让它从“好用”变成“抗打”。
信息图总览
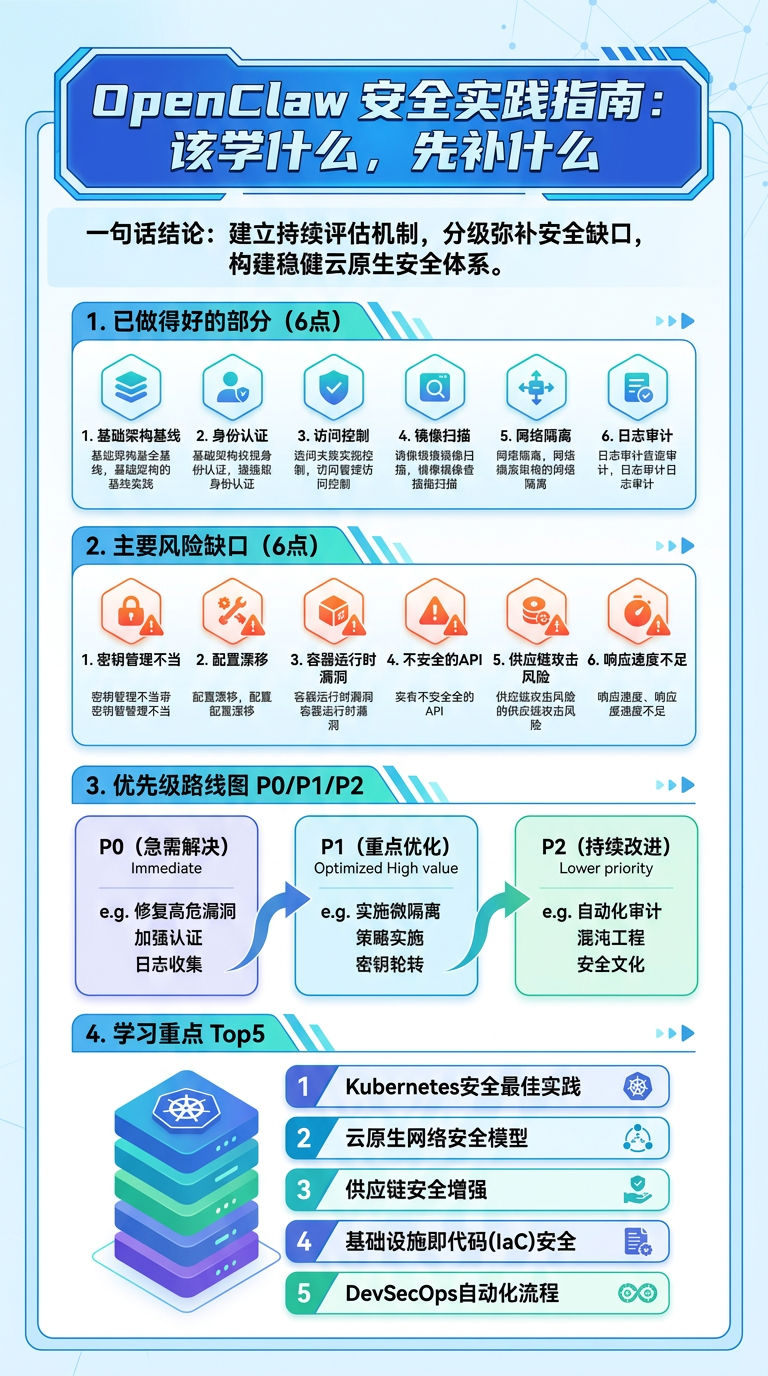
一、先说结论:这份指南值得学,但不能迷信
这份文档最可贵的地方,是它承认 AI Agent 安全不是传统主机加固的翻版,而是“提示词注入、供应链投毒、业务逻辑误执行、越权自动化”同时存在的复合风险。它把安全设计成三段式:事前(规则与审计)、事中(权限与风控)、事后(巡检与灾备),方向是对的,工程上也比空泛口号强很多。尤其是“高危必确认”和“夜间显性化巡检”两点,对降低事故概率非常有效。
但必须讲清楚:该文档里不少控制手段是“软控制”——也就是依赖模型理解、依赖 Agent 按规矩做事。一旦遇到高质量注入或模型状态波动,软控制会失效。安全体系如果只靠软控制,迟早会在某个边角场景出事。换句话说,这份指南是优秀的基础框架,不是终局方案。
二、它做对了什么:5个高价值点
- 框架完整:事前/事中/事后覆盖面广,避免“只防一段”的短板。
- 高危动作需确认:把不可逆操作从“自动执行”改成“人机共决”,收益极高。
- 对供应链有警惕:要求审计 Skill/MCP 文本与脚本,方向正确。
- 巡检指标体系清晰:13项指标把“有没有做”变成“做了什么”。
- 有灾备意识:知道要做脑区配置和状态备份,具备恢复思维。
三、真正的风险缺口:不是没规则,是缺硬约束
缺口1:行为红线太依赖模型判断。 红线规则写得再细,也可能被“同义改写、链式拆分、间接执行”绕过。只拦关键字(如 rm -rf)不是安全策略,只是最低限度提醒。
缺口2:出站控制不够硬。 文档强调“不要外发”,但如果网络默认全放行,最终仍靠 Agent 自觉。真正靠谱的是系统层白名单出站:只允许必要域名/API,其余全拒绝。
缺口3:巡检存在时间盲区。 每晚一次很好,但意味着最长24小时发现延迟。对核心配置篡改、新增可疑服务、异常出站连接,至少要有轻量实时告警。
缺口4:备份若明文,风险会迁移放大。 备份是正确方向,但若把高敏配置明文推到远端,即使私库也存在泄露半径。备份必须加密,且加密密钥与仓库分离。
缺口5:同UID权限模型天花板明显。 chmod 600 能挡“其他用户”,挡不住“同一运行身份下的恶意执行链”。要进一步提升,必须引入隔离边界(独立用户/容器/强制策略)。
四、从“能用”到“抗打”的升级路径(建议按优先级)
| 优先级 | 目标 | 为什么必须做 | 预期收益 |
|---|---|---|---|
| P0 | 最小权限 + 独立运行身份 | 降低同权限横向破坏面 | 显著降低误操作和越权后果 |
| P0 | 默认拒绝出站 + 白名单放行 | 把“外发限制”从口头变成硬规则 | 大幅减少泄露通道 |
| P0 | 备份加密与密钥分离 | 防止“灾备仓库=泄露仓库” | 恢复能力与保密性兼得 |
| P1 | 关键项实时告警 | 缩短24小时盲区 | 将发现时间从天级降到分钟级 |
| P1 | 红线从“命令字面”升级到“行为效果” | 减少语义绕过 | 提高对变体攻击的拦截能力 |
| P2 | 供应链签名/哈希+审批流水 | 降低第三方扩展风险 | 形成可追责的变更闭环 |
五、学习重点:不要泛学,按收益学
如果你准备把这份指南真正“吃透”,建议按以下顺序学习并实践:第一,Linux 最小权限与隔离(用户、组、sudo、容器边界);第二,网络出站策略(白名单思维);第三,机密管理与加密备份(避免明文配置扩散);第四,轻量主机监控(实时告警);第五,供应链审计方法(可复核、可追踪、可回滚)。这五块不是锦上添花,是让安全从“看起来严谨”变成“真的顶得住”的底盘能力。
六、最终判断:这篇文档该怎么用
我的判断很直接:这份文档可以作为你安全体系的“第一层作战手册”,但不该被当成“全部答案”。正确用法是:先按文档落地基础防线,再快速补上系统级硬约束,最后用演练持续校验。只有这样,你得到的不是“规则很多的安全感”,而是“即使模型犯错也不至于炸穿系统”的真实韧性。
一句话收尾:它是一份优秀起点,不是终点。真升级,靠组合拳——软规则负责提醒,硬约束负责兜底。