Anthropic《The Complete Guide to Building Skills for Claude》学习笔记:怎么把 AI 助手从会聊天,调成会干活
发布日期: 2026-03-10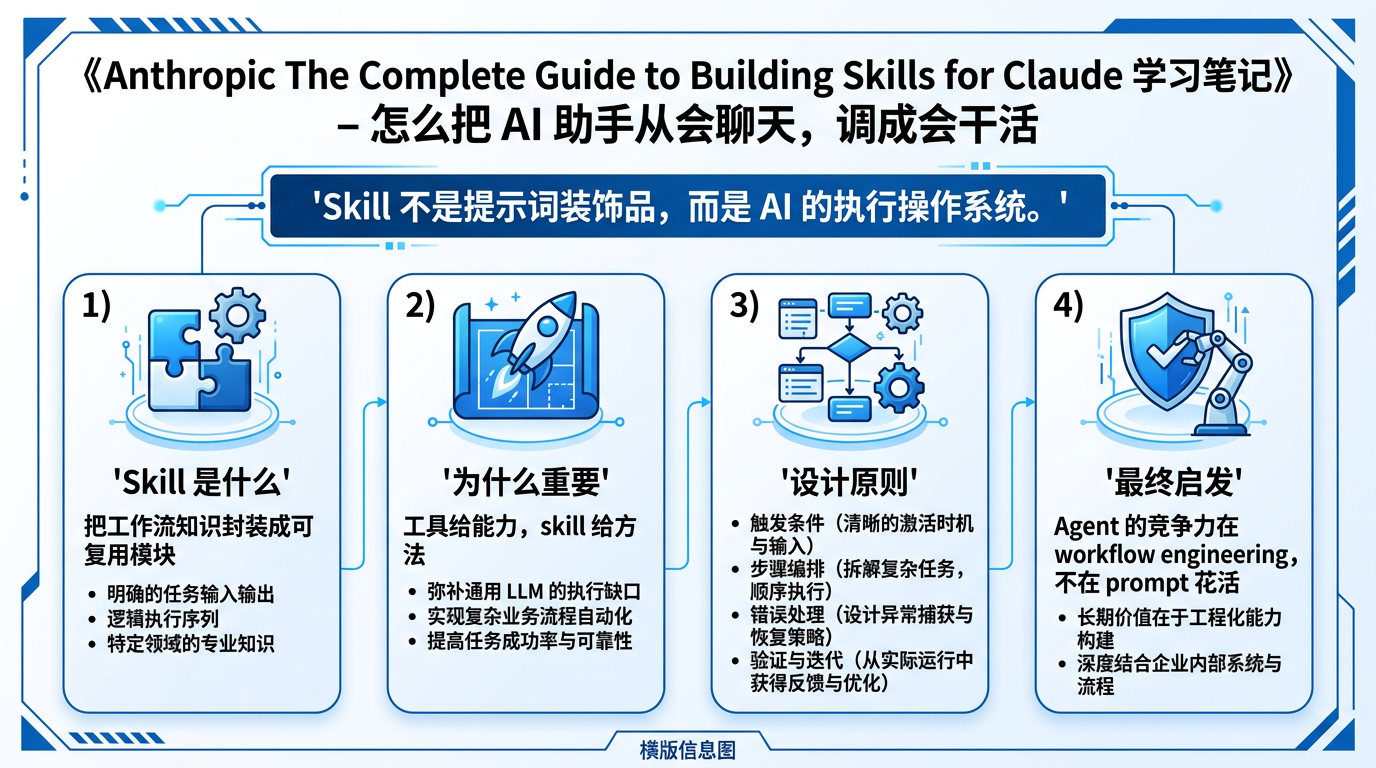
这张图把本文最重要的 4 个点压缩成一页:skill 的定义、价值、设计原则,以及对 Agent 工程化的真正启发。
这份指南最有价值的地方,不是教你怎么写一个 SKILL.md 文件,而是把一个常被忽视的真相讲明白了:真正让 Agent 稳定交付的,不只是模型能力,也不是单纯的工具接入,而是把“何时触发、按什么步骤做、遇到错误怎么办、结果怎么验收”这些工作流知识,显式封装成 skill。 说白了,skill 不是提示词花活,而是把经验、方法论和执行顺序做成可复用的操作系统。
一、这篇指南到底在讲什么
Anthropic 在这篇《The Complete Guide to Building Skills for Claude》里,试图解决一个非常现实的问题:为什么很多 AI 助手明明接了工具、接了 API、接了数据,最后还是不稳定、不一致、不好用?它给出的答案很直接——因为大部分团队只给了模型“能力入口”,却没有给它“工作方法”。
文中把 skill 定义成一个简单文件夹,里面至少要有一个 SKILL.md,还可以带脚本、参考资料和资产文件。表面看这只是打包格式,实际上它对应的是一个更深的设计哲学:把反复出现的工作流、偏好、约束、最佳实践,沉淀为可按需加载的知识模块。 这比在每次对话里重复交代一遍规则高效得多,也可靠得多。
Anthropic 很强调一个词:progressive disclosure(渐进式披露)。也就是 skill 不应该一股脑把所有内容塞进上下文,而是分三层:前言里的 YAML 元数据负责告诉 Claude“什么时候该用这个 skill”;正文负责给出核心操作说明;更细的参考资料和脚本则按需再读。这个设计非常对,因为大模型上下文本来就是稀缺资源,写得太肥,最后只会拖慢触发和执行,甚至让模型犯懒。
二、skill 到底是什么,它解决了什么问题
我觉得这篇文章最关键的洞察是:skill 的本质不是“给 Claude 增加功能”,而是“给 Claude 增加方法”。 工具告诉模型“你能做什么”,skill 告诉模型“你应该怎么做”。两者不是替代关系,而是分工关系。
文中用了一个厨房比喻:MCP 或其他连接器像专业厨房,提供食材、设备和操作空间;skill 则像菜谱,把这些原料和工具变成可重复产出的流程。这个比喻很准。很多团队接完系统就以为万事大吉,结果用户一上来还是要问:“那我现在该怎么用?”没有 skill,用户只能靠临场发挥,Claude 也只能靠猜。于是每次 prompt 都不同、工具调用顺序不同、结果质量也飘。
skill 解决的是三个老大难:
- 稳定性问题:把高质量做法固化下来,减少每次重新 prompt 的波动。
- 可复用问题:团队里一个人摸索出的最佳实践,可以变成所有人共享的默认工作流。
- 学习成本问题:用户不需要理解底层工具细节,也能直接描述目标,让 skill 代为组织步骤。
这也是为什么 Anthropic 反复强调:skill 特别适合那些可重复、多步骤、对质量一致性有要求的任务,比如研究、文档、前端设计、工单创建、项目规划、报表生成、跨系统流程自动化。简单问答不需要它,复杂执行特别需要它。
三、这份指南提出了哪些关键设计原则
文里有几条原则,我认为几乎可以当成做 Agent 的底层准则。
- 从 use case 开始,不要从工具开始。 先想清楚用户到底要完成什么,再决定 skill 怎么写、要不要调用外部系统。这个顺序非常关键。很多团队一上来先列工具,结果最后做出来的 skill 只是“工具说明书”,不是“工作流引擎”。
- 描述字段是技能触发的命门。 YAML frontmatter 里的
description不是装饰,它是 Claude 判断要不要加载 skill 的主要依据。写得泛,skill 就不触发;写得过宽,skill 就乱触发。文里说得很对:描述必须同时写清楚“这个 skill 做什么”和“用户在什么情况下会说出哪些触发语句”。 - 指令必须具体、可执行、能落地。 “先验证一下数据”这种屁话没有任何价值。要写成“运行哪个脚本、检查哪些字段、失败后怎么修”。模型不是读心术,不要指望它替你脑补流程细节。
- 把错误处理前置。 好的 skill 不是只在理想路径下好看,而是常见错误一来还能稳住。比如 API 连接失败怎么办、参数缺失怎么办、数据格式不对怎么办。Anthropic 明确建议把这些写进 skill,而不是等用户出错了再临场救火。
- 能用代码做确定性校验,就别全靠语言理解。 这点我非常认同。大模型会理解、会归纳,但它不擅长做每次都完全一致的机械校验。关键验证最好丢给脚本做,语言负责解释和组织,代码负责硬校验。
四、skill 的推荐结构,为什么其实很合理
文中给出的标准目录很简单:SKILL.md 必须有,scripts/、references/、assets/ 可选。别小看这个结构,它其实对应了一个成熟工作流系统的四个层次:
| 组成 | 作用 | 我的判断 |
|---|---|---|
| SKILL.md | 入口说明、触发条件、核心步骤 | 这是 skill 的灵魂,决定是否会被正确调用 |
| scripts/ | 确定性执行与校验 | 负责把“说得清楚”升级成“做得稳定” |
| references/ | 详细规则、文档、样例 | 避免正文臃肿,又能按需深入 |
| assets/ | 模板、字体、图标、样式 | 把输出标准化,特别适合文档和设计类 skill |
这套结构最聪明的地方,是它不假装一个 Markdown 文件能解决一切,而是承认:复杂任务一定需要“规则 + 参考资料 + 脚本 + 资产”共同配合。很多人做 Agent 失败,就失败在迷信 prompt 万能。实际上 prompt 只是入口,工程化才是交付。
五、文中最值得记住的几种模式
这份指南把常见 skill 分成几类,我觉得非常实用,特别适合拿来套自己的业务:
- 文档/资产生成类: 比如 PPT、设计稿、报告、代码骨架。这类 skill 的核心是模板、风格和质检清单。
- 工作流自动化类: 把多步操作串起来,比如创建项目、建任务、同步文件、发通知。关键在于步骤顺序、状态依赖和失败回滚。
- MCP 增强类: 不是新增工具,而是把已有工具的最佳用法教给 Claude,让调用更稳定、更像专家。
后面还给了几个模式:顺序编排、多 MCP 协调、迭代式 refinement、上下文感知工具选择、领域规则驱动执行。这些模式的共同核心只有一个:别让模型临场 improvisation,尽量把你希望它怎么做,预先写成结构。
六、这篇文章对 Agent 设计者最有价值的启发
如果你是在做 Agent、Copilot、内部助手、自动化工作流,这份文档最值得学的,不是格式,而是思路:
- 先设计“触发逻辑”,再设计“执行逻辑”。 很多团队天天调 prompt,却不重视触发条件,结果 skill 写得不错,就是永远不自动加载,等于白搭。
- 把“怎么判断成功”提前定义。 文里建议做触发测试、功能测试、性能对比。这个思路很对。没有成功标准,skill 只能靠感觉好像能用,最后就是线上玄学。
- 把人类专家经验编码成默认流程。 skill 其实是组织知识的载体。谁会把经验写成 skill,谁就能把 AI 从“个人外挂”升级成“团队基础设施”。
- Agent 真正的竞争力在工作流,不在嘴炮。 模型越来越接近,工具越来越普及,最后拉开差距的,往往不是谁会回答,而是谁会稳定完成任务。
七、这份指南的局限、偏见和容易踩坑的地方
当然,这篇文章也不是圣经,它有几个明显局限。
第一,它的前提是 Claude 生态,很多例子默认你已经在 Claude.ai、Claude Code 或 API 里工作。如果你在别的 Agent 框架里落地,结构思想可以借鉴,但具体上传、分发、API 能力未必一致。
第二,它对“描述字段驱动触发”这件事非常乐观,但实际生产环境里,触发从来不是 100% 靠描述就能解决。你要面对多轮上下文、语言歧义、多个 skill 竞争、用户表达很烂等情况。文中给了 90% 触发率这种目标,但在复杂真实系统里,这已经算高标准了,不是轻轻松松就能做到。
第三,它虽然提到“代码比语言更确定”,但还是偏保守,没有把“校验器、状态机、策略路由器”这些更硬核的机制讲透。对于企业级 Agent 来说,skill 很重要,但光靠 skill 仍然不够,你还需要监控、回滚、权限分层、审计日志、人工接管点。
第四,它默认 skill 越多越好地模块化,但现实里 skill 一多,冲突、误触发、上下文膨胀、用户困惑都会上来。没有治理机制,skills 很容易从“能力库”变成“垃圾堆”。
八、给中国开发者和产品经理的一份可执行学习清单
如果你想真把这篇指南学到手,不要只看,直接按下面这套做:
- 挑一个你们团队每周至少重复 5 次的任务,比如日报、项目建单、客户跟进、竞品分析。
- 把这个任务拆成 4 到 8 步,写清楚每一步需要什么输入、调用什么工具、输出什么结果。
- 写一个最小版 skill:先只做一个 use case,不要贪大求全。
- 重点打磨
description,把用户真实会说的话写进去,而不是写产品经理自嗨的术语。 - 给 skill 加 3 类测试:该触发的要触发、不该触发的别乱触发、执行结果要稳定。
- 把最容易错的地方做成脚本校验,不要只靠文字提醒。
- 上线后看三件事:用户有没有老是手动点 skill、有没有频繁纠正流程、有没有 API 调用失败。
- 每出现一个新坑,就把坑写回 skill,而不是寄希望于模型下次自己聪明点。
这最后一点尤其重要。skill 不是写完就结束,它本质上是一个会不断长大的操作手册。谁把失败案例写进去,谁的 Agent 就会越来越稳;谁每次都靠“再试一次”,谁就永远停留在演示阶段。
九、我的总评
这篇指南值不值得学?值,而且很值。 它最大的贡献,是把“AI 助手工程化”这件事讲得很接地气:不是玄学,不是 prompt 炼丹,而是围绕 use case、触发、步骤、验证、分发、迭代,建立一套可执行的方法。
但它也有边界。你如果把它当成“写个 skill 文件就能做出企业级 Agent”,那就是想屁吃。真正成熟的 Agent 系统,skill 只是中层知识封装,往下还要靠工具、脚本、权限和基础设施,往上还要靠产品体验、观察指标和人工介入机制。
所以这篇文章最该学到的,不是格式模板,而是一个硬道理:让 AI 干活,必须把专家方法显式化、结构化、可验证化。 说得再直白一点,未来谁掌握“workflow engineering”,谁就能把同样的模型,调教出完全不同的生产力等级。